If you’ve read our blog post False rumors do not spread like true ones you will probably recognize this graph:
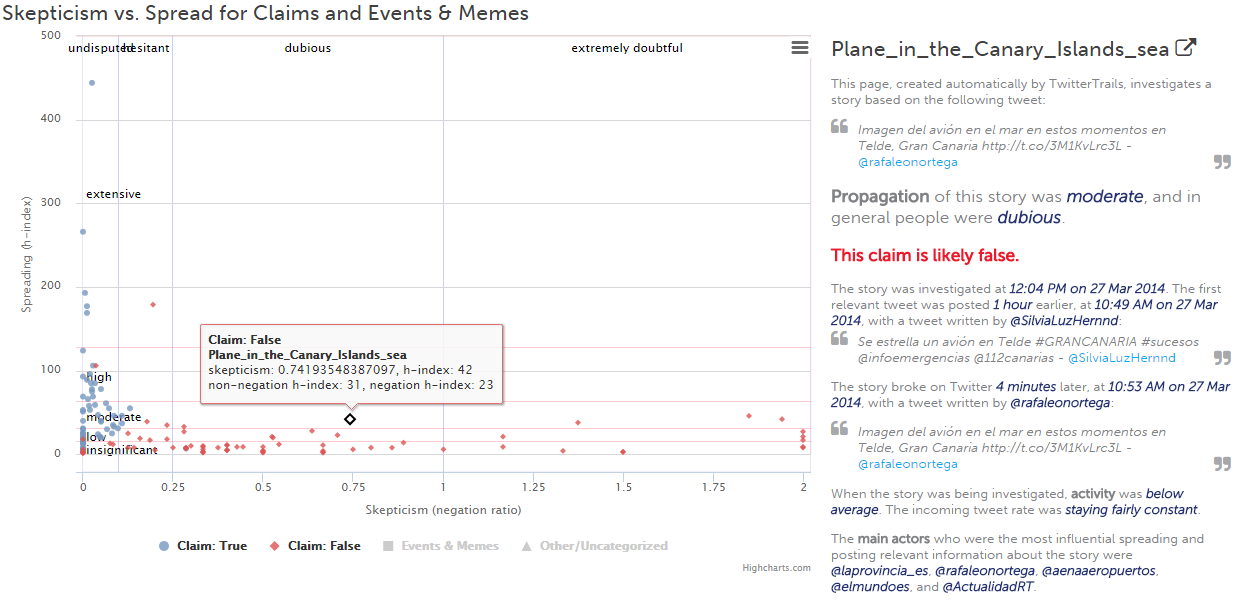
It plots the skepticism of TwitterTrails stories vs. their spread, contrasting how much doubt people have in the information a story presents and how visible and discussed a story was (read more about Spread and Skepticism here). This graph is now visible to the public, and you can view the skepticism and spread of all the stories in our database: RUMOR SPREAD vs SKEPTICISM graph (hovering over a point displays skepticism and spread, and clicking brings up a summary of the story)
Continue reading for more information about this graph, and how TwitterTrails determines whether claims are likely true or false based on the wisdom of the crowd on Twitter.
We have found that, on Twitter, false claims spread less and are questioned more than true claims (we have determined the claims labeled true and false in this graph by hand, through outside sources such as traditional news media and snopes.com). When people are doubtful of the information in a tweet, they appear to be less likely to retweet it (though they may still discuss it in their own tweets), resulting in the information spreading less than information they believe. There are exceptions, where tweets that present false information receive many retweets, and even stories on TwitterTrails that were false being widely discussed, but the general trend is that on Twitter, false claims have much less visibility (this is not true for all social media websites, Facebook being a good example).
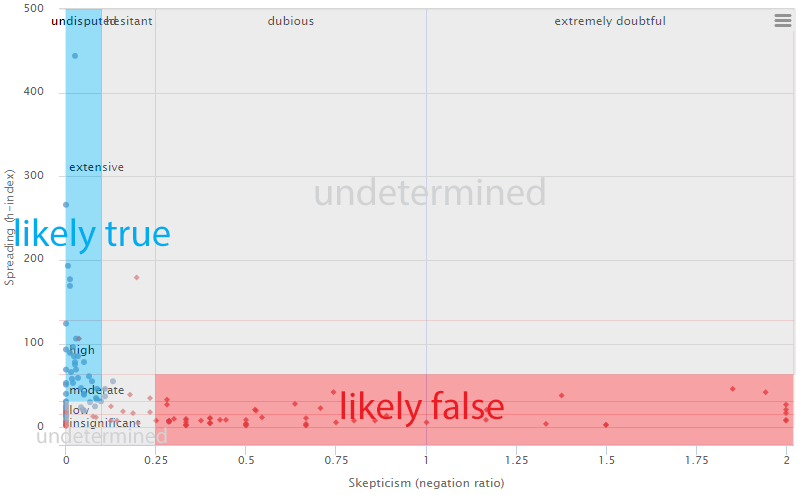
Based on this assumption, that false claims will have a lower spread and higher skepticism, we have also create an algorithm that will label a story as either “likely true” or “likely fase” based on these two crowd metrics. Stories with low or insignificant spread and skepticism that is dubious or extremely doubtful are deemed likely false, while stories with moderate, high, or extensive spread and undisputed skepticism are considered likely true.

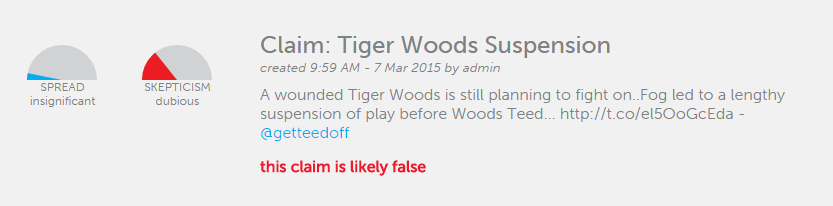
What’s next? We are currently working on training a Machine Learning classifier to make determinations as to whether a claim is likely true or false, based on how the crowd behaved on Twitter.